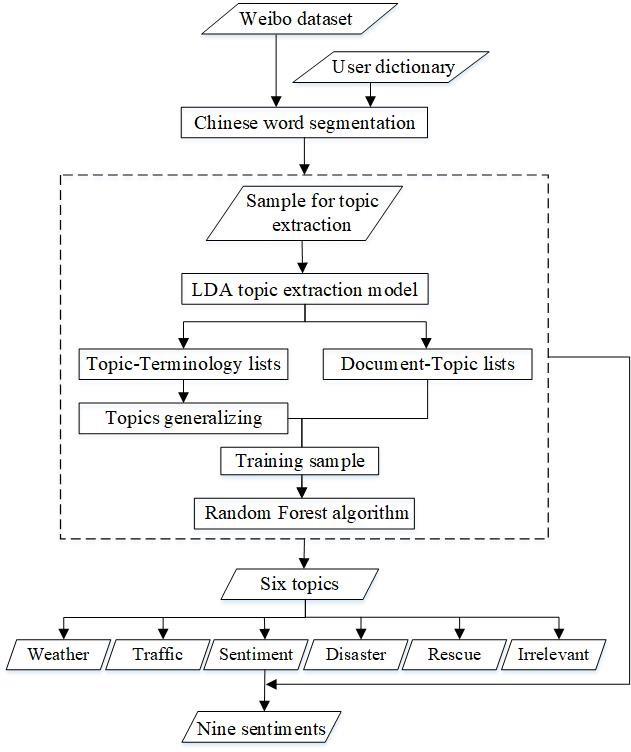
A topic extraction and classification model, combining the Latent Dirichlet allocation (LDA) model and the Random Forest (RF) algorithm, was used to process flood-related Weibo texts. The first step was to mine and generalize the topics from the flood-related Weibo sample using the LDA model. Then, the topic extraction results were utilized as training samples for the RF algorithm to classify the whole Weibo data. The flood-related Weibo were generalized into six topics: “weather warning”, “traffic conditions”, “rescue information”, “public sentiment”, “disaster information”, and “other.” A secondary classification was implemented to divide the broad topic of “public sentiment” into nine more detailed sentiments, including “the disaster situation”, “questioning the government and media”, “seeking help”, “praying for the victims”, “feeling sad about the disaster”, “making donations”, “thankful for the rescue”, “worrying about vegetable prices”, and “other”. Some additional steps (e.g., Chinese word segmentation) were needed to implement the model, which are shown in Figure 2.
(1) Word Segmentation
Chinese word segmentation was necessary after the data acquisition and pre-processing because there is no obvious separator between Chinese words. A Python package for Chinese text segmentation, called “Jieba” was utilized. By building a user dictionary including keywords related to the Shouguang flood and names of the administrative places of Shouguang City, the package segmented words efficiently. After this process, stop words were removed as they are the most common words and lack valuable information.
(2) The LDA model
The topics of the Weibo texts were extracted by the LDA model. LDA is a Bayesian probability model that has three layers of “document-topic-word”, with which to identify the semantic topic information in large-scale document sets or corpus. In LDA, documents are represented as random mixtures over latent topics, each of which is characterized by a distribution of words [24]. This unsupervised machine learning technique has recently emerged as a preferred method for working with large collections of text documents. The “Gensim” package in Python was used to implement the LDA model. The optimal number of initial topics was 20, for the LDA model repeated experiments. The topic-terminology lists and the document-topic lists were obtained from the LDA model. The topic-terminology lists are the vocabularies of each initial topic and the frequency with which those vocabularies occur. The Document-Topic lists show the probability that each Weibo text is associated with each of the initial 20 topics. We assigned each Weibo text to the topic it most closely resembled according to the probabilities in the document-topic lists. Based on the topic-terminology lists, the initial 20 topics were generalized into six (“nine” in the secondary classification) by merging similar topics and discarding the irrelevant ones.
(3) The RF algorithm
The RF algorithm was used to classify the Weibo texts into different topics. Random forests are a combination of tree predictors, wherein each tree depends on the values of a random vector sampled independently and there is the same distribution for all trees in the forest . The RF classifier is considered a top-notch supervised algorithm in a wide variety of automatic classification tasks.
The RF algorithm was implemented by a machine learning package named “scikit-learn” in Python. Based on the document-topic lists obtained from the LDA model, 3000 annotated Weibo texts were used as training samples and 600 annotated Weibo texts were used as test sets. The number of classification trees (n_estimators) was an important parameter for the classification accuracy [24]. We used the out-of-bag (OOB) outputs to determine the optimized values of the parameters to 200.
Comment list ( 0 )

