
Vector Data Structure and Its Coding
Vector Data Structure
Definition
Another common graphic data structure in Geographic Information System is vector structure, that is to say, geographic entities such as points, lines and polygons are represented as accurately as possible by recording coordinates. The coordinate space is set as continuous, allowing precise definitions of arbitrary positions, lengths and areas. In fact, its accuracy is only limited by the accuracy of digital equipment and the length of digital records. In this case, the accuracy is much higher than that of the grid structure.
For point entities, only their coordinates and attribute codes are recorded in the vector structure. For line entities, the digitizination is the quantization. A curve is represented by a series of sufficiently short straight lines joined at the beginning and ending. When the curve is divided into many and short line segments, these small line segments can be approximated as straight line segments, and the curve can also be accurately divided by a series of lines. These small line segment sequences represent that only the coordinates of the endpoints of these segments are recorded in the vector structure, and the curves are represented as a coordinate sequence. The coordinates are considered to be connected by line segments, which can vividly represent the linear objects of various shapes within a certain precision range. Polygon is a spatial area with arbitrary shape and completely closed boundary in the geographic information system. Its boundary divides the whole space into two parts: the part containing the infinite point is called the exterior, and the other part is called the interior of the polygon. A closed area is called a polygon because the boundary line of the area, like the line entity introduced earlier, can be regarded as a series of multiple and short line segments, each small line segment as a side of the area, so this area can be regarded as a polygon composed of these edges.
Tracking digitizer generates vector structure digital map for map digitization, which is suitable for vector plotter drawing. Vector structure allows the most complex data to be stored with minimal data redundancy. Compared with raster structure, data has high accuracy and occupies less space. It is an efficient spatial data structure.
Characteristic
The characteristics of vector structure are obvious location and implicit attributes, which are stored directly according to coordinates, while attributes are generally stored in some specific locations in the file header or data structure. This feature makes the algorithm of graphics operation more complex than raster data structure on the whole, and some are even difficult to implement. Of course, some places are also convenient and unique. In the operations of length, area, shape, graph editing and geometric transformation, the vector structure has high efficiency and accuracy, while in the operations of superposition and neighborhood search, it is more difficult.
coding method
Point entity
Vector coding of point and line entities is relatively direct, as long as the spatial information and attribute information can be recorded completely. Points are geographic entities that can no longer be separated in space. They can be concrete or abstract, such as terrain points, text location points or nodes of line segment networks, etc. They are represented by a pair of X and Y coordinates. Figure 7-8-a shows the basic content of point vector coding.
Line entity
Line entities are mainly used to represent symbolic lines and polygonal boundaries of linear objects (such as highways, river systems, ridges, etc.), sometimes also known as “arcs”, “chains” and “strings”. Their vector coding generally includes the following contents. Figure 7-8-b is the basic content of vector coding of line entities.
Among them, the unique identification code is the system permutation serial number. The line identification code can identify the type of line, and the starting and ending point numbers can be directly expressed in coordinates. The display information is the text or symbol when displayed, and the non-geometric attributes associated with the line can be directly stored in the line file, or can be stored separately, and searched by the identification code.
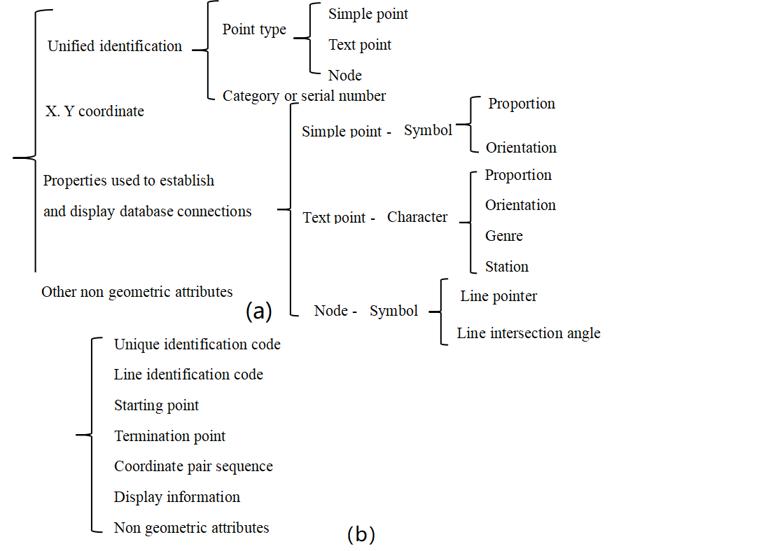
polygon
Polygon data is the most important type of data to describe geographic information. In regional entities, those with name attributes and classification attributes are usually represented by polygons, such as administrative areas, land types, vegetation distribution, etc., those with scalar attributes are sometimes described by contours (such as topography, rainfall, etc.).
Polygon vector coding not only expresses location and attributes, but also expresses the topological properties of regions, such as shape, neighborhood and hierarchy, so that these basic spatial units can be displayed and manipulated as thematic map data. Because of the abundant information to be expressed and the complex operation based on polygon, polygon vector coding is more efficient than point and line-based coding. Volume vector coding is much more complex and important.
In addition to the requirement of storage efficiency, polygon vector coding generally requires that the polygons represented have their own independent shapes, and can calculate their perimeters and areas, and other geometric indicators. The recording methods of the topological relationships of polygons should be consistent in order to carry out spatial analysis. The hierarchy of regions, such as the island-lake-island relationship, should be clearly expressed. Therefore, it is quite different from the coding designed by computer-aided cartography system for display and cartography purposes.
1) Coordinate Sequence Method (Spaghetti Method)
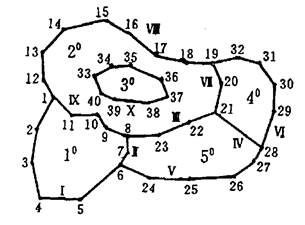
The simplest polygon vector coding is composed of X and Y coordinate pairs of polygon boundary and description information. Fig. 7-9 shows the following coordinate files:
10:x1,y1;x2,y2;x3,y3;x4,y4;x5,y5;x6,y6;x7,y7;x8,y8;x9,y9;x10,y10;x11,y11;
20:x1,y1;x12,y12;x13,y13;x14,y14;x15,y15;x16,y16;x17,y17;x18,y18;x19,y19;x20,y20;x21,y21;x22,y22;x23,y23;x8,y8;x9,y9;x10,y10;x11,y11;
30:x33,y33;x34,y34;x35,y35;x36,y36;x37,y37;x38,y38;x39,y39;x40,y40;
40:x19,y19;x20,y20;x21,y21;x28,y28;x29,y29;x30,y30;x31,y31;x32,y32;
50:x21,y21;x22,y22;x23,y23;x8,y8;x7,y7;x6,y6;x24,y24;x25,y25;x26,y26;x27,y27;x28,y28;
The file structure of coordinate sequence method is simple, and it is easy to realize the operation and display of polygon. The disadvantages of this method are:
(1.1) The common boundary between polygons is digitized and stored twice, resulting in redundant and debris polygons;
(1.2) Each polygon has its own system and lacks neighborhood information, which makes it difficult to process neighborhood, such as eliminating the common boundary between two polygons;
(1.3) The island is constructed as a single figure without any connection with the outsourcing polygon;
(1.4) It is not easy to check for topological errors. This method can be used in simple rough precision mapping system.
2) Tree Index Coding
The method uses tree index to reduce data redundancy and indirectly increase neighborhood information. The method digitizes all boundary points, stores coordinate pairs in order, connects point index with boundary line number, leads each polygon by clues, and forms tree index structure.
Figures 7-10 and 7-11 are respectively polygonal and line file tree index sketches of Figure 7-9. Its document structure is as follows:
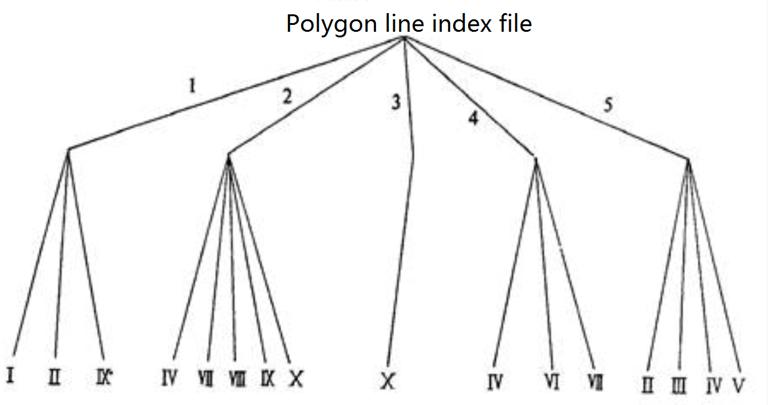
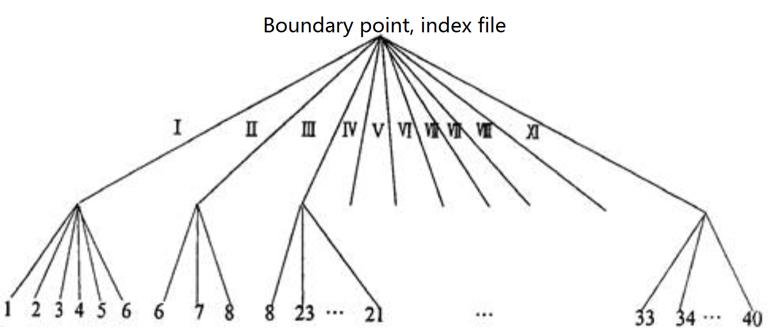
Using the above tree structure, the polygon data of Figure 7-9 are recorded as follows:
Point file
Order number |
coordinate |
1 |
x:sub:`1`,y:sub:`1` |
2 |
x:sub:`2`,y:sub:`2` |
… |
… |
40 |
x:sub:`40`,y:sub:`40` |
Line file
Line number |
Starting point |
Ending point |
Order number |
I |
1 |
6 |
1,2,3,4,5,6 |
II |
6 |
8 |
6,7,8 |
… |
… |
… |
… |
X |
33 |
33 |
33,34,35,36,37,38,39,40,33 |
Polygonal Documents
Polygon Number |
Polygon Boundary |
10 |
I, II, IX |
20 |
III, VII, VIII, IX, X |
30 |
X |
40 |
IV, VI, VII |
50 |
II, III, IV, V |
Tree index coding eliminates the problem of data redundancy and inconsistency between adjacent polygon boundaries. When simplifying overly complex boundary lines or merging adjacent polygons, it is not necessary to modify the index table. Neighborhood information and island information can be obtained through the clue processing of polygon files, but it is more cumbersome. Therefore, the adjacent functions are operated to eliminate unnecessary edges and process island information. It is difficult to check the topological relationship, and both coding tables need to be built manually, which is workload and error-prone.
3) Topological Structure Coding
To solve the problem of neighbourhood and island information processing thoroughly, we must establish a complete topological relationship structure, which includes the following contents: unique identification, polygon identification, outsourcing polygon pointer, adjacent polygon pointer, boundary link, range (maximum and minimum x, y coordinate values). Topological structure coding can solve the problem of spatial relational query, but it increases the complexity of the algorithm and the size of the database.
The most important thing of vector coding is the integrity of information and the flexibility of operation, which is determined by the characteristics of vector structure itself. At present, there is no uniform and optimal vector structure coding method. In specific work, it should be flexibly designed according to the characteristics of data and the requirements of tasks.
DIME (Dual Independent Map Encoding) Coding System
DIME is developed by the US Census Bureau on the basis of census. It establishes the topological relationships among polygons, boundaries and nodes by directed coding. DIME coding is the basis of other topological coding structures.
