Based on Weibo Application Programming Interfaces (APIs), microblogs related to COVID-19 were collected with ‘pneumonia’ and ‘coronavirus’ as the keyword between 00:00 on January 9, 2020 and 24:00 on March 10, 2020. The following information was extracted: user ID, timestamp (i.e., the time at which the message was posted), text (i.e., the text message posted by a user), and location information. After text filtering, 3,427,933 Weibo messages were selected, including 197,118 texts with geographical location information.
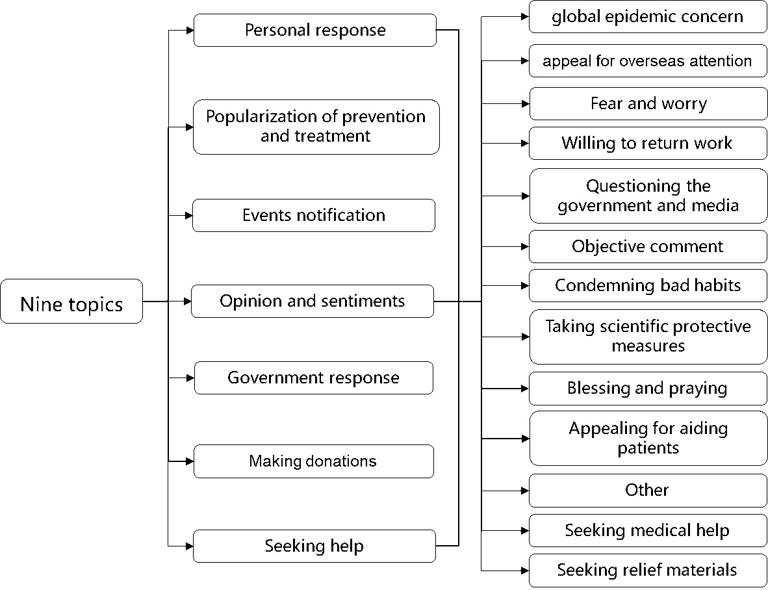
A topic extraction and classification model combining the LDA model and the random forest (RF) algorithm was used to hierarchically process COVID-19-related Weibo texts. The first step was to mine and generalize the topics from the COVID-19-related Weibo sample using the LDA model. Then, topic extraction results were utilized as training samples for the RF algorithm to classify the Weibo data. As shown in Figure 1, the COVID-19-related Weibo were generalized into seven topics: ‘events notification’, ‘popularization of prevention and treatment’, ‘government response’, ‘personal response’, ‘opinion and sentiments’, ‘seeking help’, and ‘making donations. A secondary classification was implemented to divide ‘personal response’, ‘opinion and sentiments’, and ‘seeking help’ into thirteen detailed sub-topics, including ‘fear and worry’, ‘questioning the government and media’, ‘condemning bad habits’, ‘objective comment’, ‘taking scientific protective measures’, ‘blessing and praying’, ‘appealing for aiding patients’, ‘willing to return work’, ‘seeking medical help’, ‘seeking relief materials’, ‘appeal for overseas attention’, ‘global epidemic concern’, and ‘other’.